How hidden scoring patterns shape hiring decisions
Most hiring leaders assume their interview process is reasonably consistent.
After all, organizations use scorecards, structured questions, and evaluation rubrics. If everyone follows the same framework, the thinking goes, decisions should naturally converge on the strongest candidates.
But something very different usually happens.
Interview scoring is influenced by personality, risk tolerance, experience, perception, and cognitive bias. Over time, those factors create recognizable patterns in how individual interviewers evaluate candidates.
These patterns are rarely visible because most organizations only track pipeline efficiency metrics:
- Time-to-fill
- Pass-through rates
- Offer acceptance
Those metrics measure speed. They do not measure decision quality.
When interviewer scoring behavior is visualized across many evaluations, patterns begin to emerge. What appears to be subjective judgment, frequently dismissed as unquantifiable “soft skills,” actually produces measurable signals.
These signals expose an important reality: aspects of hiring long treated as unmeasurable are simply unmeasured. Once captured, decision quality metrics reveal how different interviewers interpret the same candidate evidence in very different ways.
What the data reveals
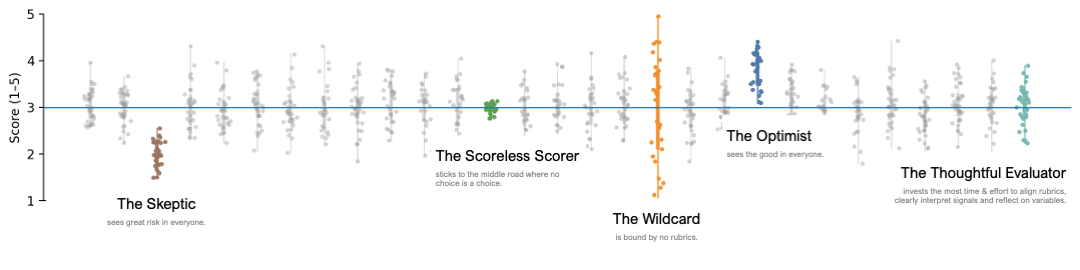
Each column represents one interviewer. Each dot represents a score submitted during an interview evaluation.
5 interviewer scoring personas
At first glance the variation may appear random. In reality, it reflects consistent evaluation styles that influence hiring outcomes.
While every interviewer is unique, most scoring behavior clusters into a few recognizable patterns that reflect an interviewer’s implicit approach to evaluating candidates.
The Skeptic
The Skeptic scores candidates in very similar ways that are statistically unlikely. Their scores are consistently lower than average, even when candidates perform well.
Skeptics often believe they are maintaining high standards. In reality, their evaluations may introduce systematic severity bias, eliminating strong candidates early in the process.
The Scoreless Scorer
The Scoreless Scorer prefers to use almost entirely neutral rankings, clustering tightly around the midpoint.
While this behavior may feel “fair,” it creates a different problem: a lack of signal. If every candidate receives nearly identical neutral scores, the evaluation framework cannot distinguish strong candidates from weak ones.
The Wildcard
The Wildcard shows no predictable pattern. Scores swing widely from one evaluation to another in ways rarely reflected in accurate scoring models.
This variability may result from shifting interpretations of the rubric, inconsistent questioning, or reliance on intuition rather than structured evaluation.
Wildcard behavior introduces noise into hiring decisions, making outcomes harder to explain or defend.
The Optimist
The Optimist sees immense potential in each candidate and scores many evaluations well above the midpoint.
Optimists are often enthusiastic interviewers who enjoy identifying strengths in candidates. However, when their scoring distribution drifts significantly above average, it can distort comparisons between candidates.
The Thoughtful Evaluator
The Thoughtful Evaluator demonstrates the most balanced scoring distribution.
Rather than defaulting to optimism or skepticism, they carefully measure the candidate against the role requirements, signals observed during the interview, and the evaluation rubric.
Their scoring distribution reflects calibrated judgment, which is the goal of structured evaluation systems.
Why calibration drifts over time
Even when organizations begin with strong interview training and clear rubrics, evaluation standards rarely remain stable.
Several forces gradually introduce drift:
- Team growth
New interviewers join the process with different interpretations of evaluation criteria. - Memory decay
Calibration sessions happen infrequently, and interviewers forget the rationale behind scoring standards. - Hiring pressure
When teams urgently need to fill roles, evaluators may relax or tighten standards without realizing it. - Narrative bias
Strong personal impressions often override structured signals.
Over time, these forces cause the definition of a “strong candidate” to shift subtly across interviewers and teams.
The result is hidden variability in hiring decisions.
Measuring decisions
Most recruiting analytics measure pipeline efficiency, but very few measure evaluation integrity.
Decision science introduces a different set of metrics designed to evaluate whether hiring decisions are consistent, explainable, and predictive.
Examples include:
- Decision Consistency Rate
How often similar candidate profiles produce similar decisions across interviewers. - Override Frequency
How often hiring decisions contradict structured evaluation thresholds. - Screening Predictive Strength
Whether early evaluation signals actually predict downstream interview outcomes. - False Negative Risk
The estimated likelihood that strong candidates are rejected early in the process. - Decision Drift Index
How evaluation standards shift across time, teams, or hiring waves.
These metrics focus on decision quality, not just pipeline speed.
How AI can improve consistency
Structured evaluation frameworks already exist in most organizations, but humans struggle to apply them consistently.
Interviewers operate in environments that are:
- fast-moving
- socially complex
- cognitively demanding
Expecting perfect calibration from human evaluators in those conditions is unrealistic.
AI can assist by doing what humans struggle to do reliably:
- remembering evaluation criteria
- recognizing scoring patterns
- detecting decision drift
- surfacing inconsistencies in real time
This does not replace human judgment.
Instead, it strengthens it.
AI provides the measurement layer that turns interview decisions from informal opinions into structured, analyzable signals.
From intuition to infrastructure
Hiring decisions shape teams, compensation, careers, and culture. Yet most organizations still treat evaluation as a largely intuitive process.
Interviewers are asked to apply structured rubrics while simultaneously managing conversation, interpreting signals, and forming impressions. In these conditions, perfect calibration is unrealistic.
Decision science offers a different approach. Instead of assuming evaluation quality, we measure it.
Metrics like Decision Consistency, Predictive Strength, and False Negative Risk make it possible to evaluate whether hiring decisions are stable, explainable, and aligned with organizational goals.
AI does not replace human judgment in this process. It strengthens it.
By tracking scoring patterns, identifying drift, and surfacing hidden inconsistencies, AI turns hiring decisions into structured signals that can be analyzed, improved, and trusted.
The goal is not simply faster hiring.
It is more reliable decision making.
This analysis is part of my Decision Integrity metrics framework, which helps organizations measure the quality and consistency of hiring decisions.
Need to talk hiring systems?
I help companies:
- Audit their recruiting workflows
- Eliminate vendor sprawl
- Design AI-ready funnel architecture
- Build internal AI agents
- Create automations that actually get adopted
If you're exploring AI adoption — or your pilot is stuck — I'd love to help.
👉 Let’s connect: dianewilkinson510@gmail.com
👉 Portfolio: dianewilkinson.github.io
👉 LinkedIn: linkedin.com/in/dianewilkinson
Tags
Let's calibrate your interview process.
I design decision integrity systems that surface scoring patterns, reduce bias, and make interview quality measurable.